AGI For Developers
- AGI For Developers
- Open AI 入门
- Open AI 提示词工程与进阶使用^prompt-engineering
- 如何设定 ChatGPT API 函数参数?
- 如何让 ChatGPT 保留上下文记忆?
- 如何给 ChatGPT 撰写更好的Prompt提示词? ^openai-prompt-engineering
- 1. 写清楚的指示(Write clear instructions )
- 2.提供参考文本 ( Provide reference text )
- 3. 将复杂的任务分解为简单的子任务 (Split complex tasks into simpler subtasks)
- 3.1 使用意图分类来识别用户查询的最相关的指令 (Use intent classification to identify the most relevant instructions for a user query)
- 4.2 对于需要非常长的对话的对话应用程序,请总结或过滤以前的对话 (For dialogue applications that require very long conversations, summarize or filter previous dialogue)
- 4.3 递归地分段总结长文档 (Summarize long documents piecewise and construct a full summary recursively)[^summarizing-books]
- 4. 给GPTs一些时间来“思考” (Give GPTs time to "think" )
- 5. 使用外部工具 (Use external tools )
- 6.系统地测试变化( Test changes systematically )
- 如何使用 思维链 (Chain of Thought)帮助模型处理复杂的问题?[^chain-of-thought]
- 如何使用 少样本学习 (Few Shot)的到自己想要的结果?
- 如何 OpenAI 的对话中进行函数调用?^openai-chat-function
- Open AI 的其他模型
- 开源模型
- 产品、运维与生产实践
Open AI 入门
如何设置 OpenAI API?
基本概念
- AIaaS: 是人工智能即服务,是一种通过云计算平台提供人工智能服务的方式。与之相反的是,传统的人工智能服务需要用户自己搭建服务器、安装软件、配置环境等。
- API: 是应用程序接口,是一种软件的功能的描述,是应用程序与开发者之间的桥梁。
- OpenAI: 是开展人工智能研究的公司,其研究成果包括 GPT-3、GPT-4、ChatGPT、DALL-E、CLIP 等。
- OpenAI API: 是 OpenAI 提供的 API,是一种用于调用 OpenAI 模型的接口。可以提供文本补全、文本生成、文本向量化、文本审查、图片生成、语音转文字等功能。
- API KEY: 是 API 的密钥,是一种用于验证的字符串,用于验证 API 的使用者是否有权限使用 API。
如何获取 OpenAI API KEY?
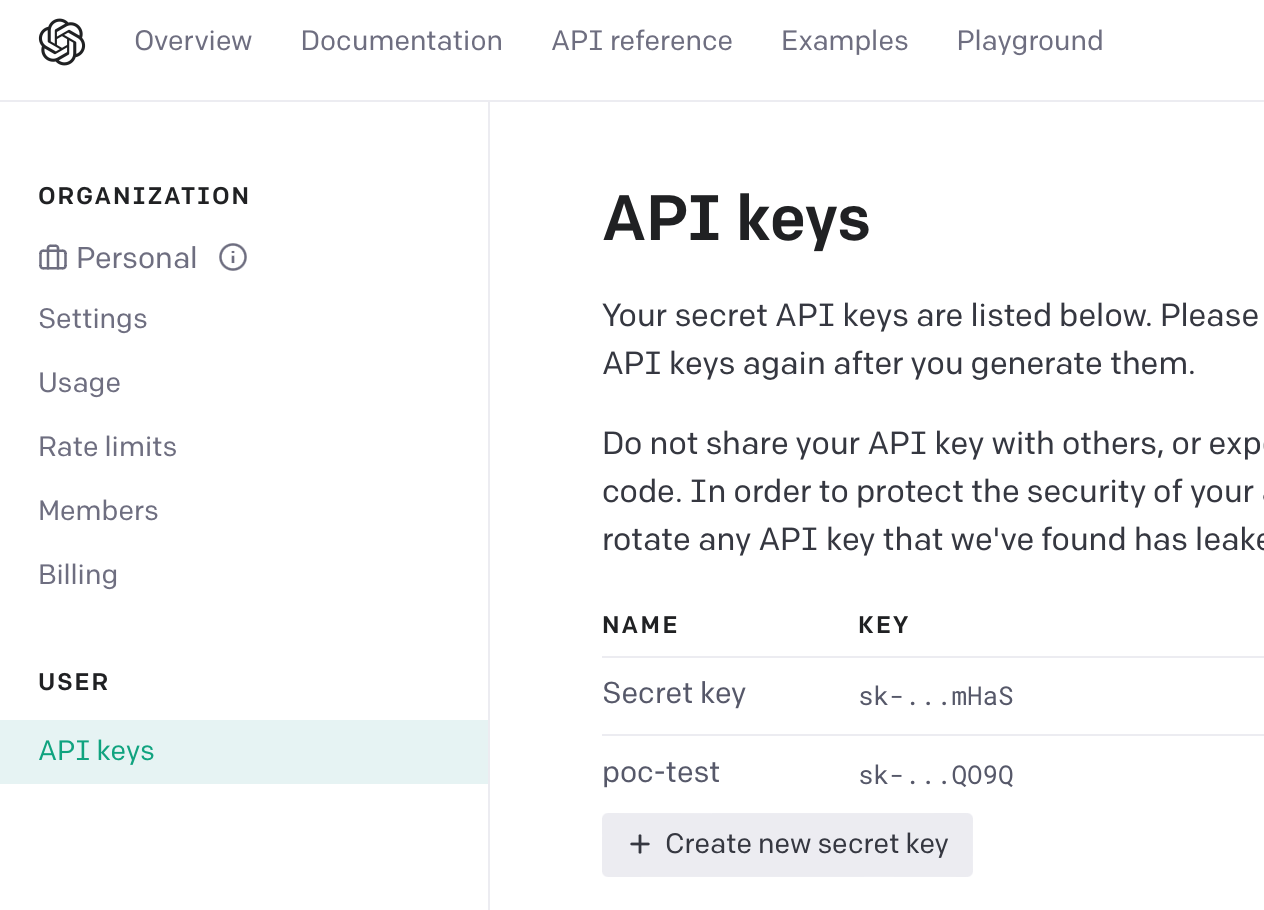
- 点击
Create new secret key按钮
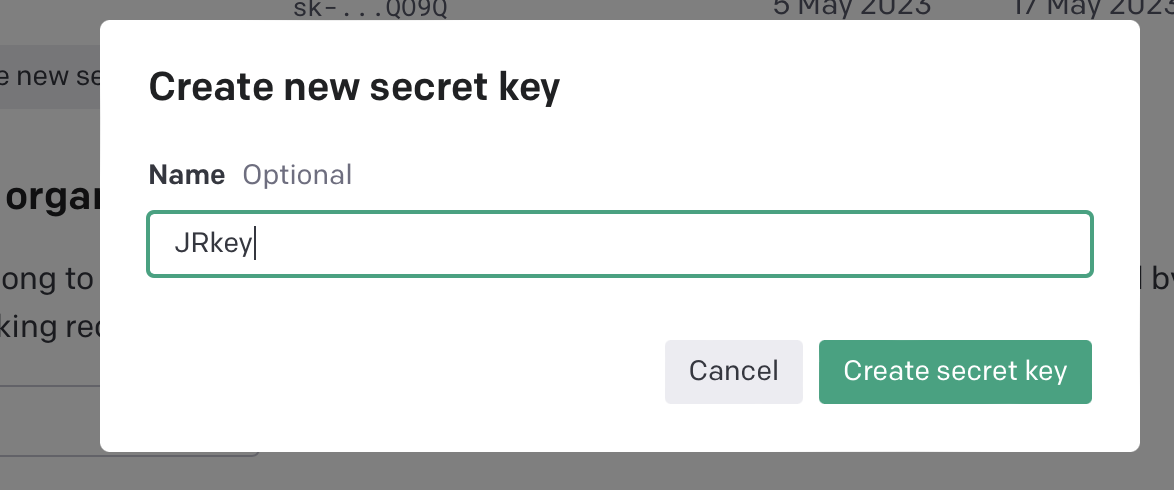
- 输入 API KEY 的名称,点击
Create按钮
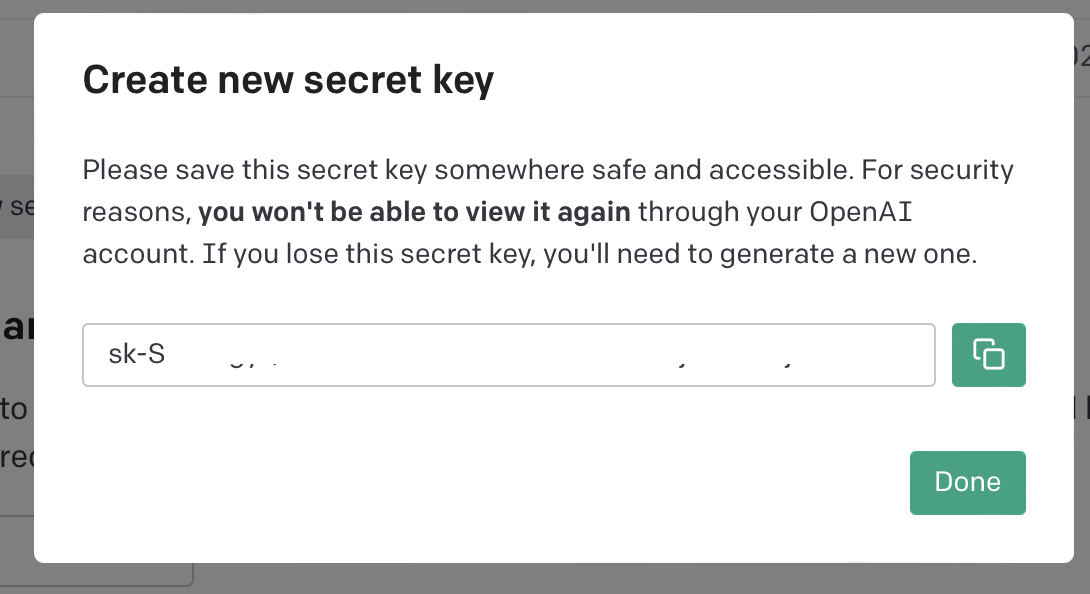
- 复制 API KEY 到本地 .env 文件中
OPENAI_API_KEY=sk-xxxxxxxxxx
# 请将 sk-xxxxxxxxxx 替换为自己的 API KEY
同时使用dotenv包来读取本地的.env文件
- 在本地项目中使用 API KEY
require('dotenv').config(); // 引入 dotenv 模块,同时加载 .env 文件中的环境变量(即 API KEY)
const OPENAI_API_KEY = process.env.OPENAI_API_KEY;
const { Configuration, OpenAIApi } = require("openai");
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
const response = await openai.createCompletion({
model: "text-davinci-003",
prompt: "Q: Where is the Valley of Kings?\nA:",
temperature: 0,
max_tokens: 100,
top_p: 1,
frequency_penalty: 0.0,
presence_penalty: 0.0,
stop: ["\n"],
});
console.log(response.data);
成功返回结果,说明 API KEY 设置成功
{
"id": "cmpl-3QJZ5Z5Z1Z5Z5",
"object": "text_completion",
"created": 1629785189,
"model": "gpt-3.5-turbo",
"choices": [
{
"text": "The Valley of the Kings is located in Egypt, on the west bank of the Nile River in Luxor.",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
]
}
如何与 OpenAI 进行对话?
基本概念
- 语言模型: 泛指所有用于文本预测的模型,这类模型可以在给定一段文本的情况下,预测下一个单词或者下一个句子的出现概率。例如:
今天天气很好,我想去...,那么语言模型会预测出公园 - 大语言模型(LLM): 是使用超大规模数据训练的语言模型,例如:GPT-3、GPT-4、ChatGPT 等。
- 对话模型: 是一种用于生成对话的模型,是一种用于预测下一个回答的模型。例如:
Q: 墨尔本位于哪个国家?, 那么对话模型会预测出澳大利亚。适用场景包括:客服机器人、聊天机器人等、虚拟助手等,比如:小爱同学、Siri等 - ChatGPT: 是OpenAI提供的对话模型,是一种用于生成对话的大语言模型
- 提示词(Prompt): 是一种用于提示模型的文本,可以让用户根据提示进行输入,从而引导语言模型生成更加符合用户需求的回复。
使用 OpenAI 进行对话
require('dotenv').config(); // 读取本地.env 文件
const OPENAI_API_KEY = process.env.OPENAI_API_KEY;
const { Configuration, OpenAIApi } = require("openai");
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
const completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{"role": "system", "content": "You are a helpful assistant."},
{role: "user", content: "墨尔本位于哪个国家?"}],
});
console.log(completion.data.choices[0].message);
消息中的 role 有三种类型:user, system, assistant。其中 user 是用户,system 是系统, assistant 是对话机器人。
如何选择 OpenAI 的对话模型?
基本概念
- 不同的语言模型: OpenAI 提供了不同的语言模型,例如:
gpt-3,gpt-3.5,gpt-3.5-turbo等。每个模型都来自不同的基础数据集,有不同的使用效果,和不同的费用。
可以使用以下代码获取所有的模型列表:
require('dotenv').config(); // 读取本地.env 文件
const OPENAI_API_KEY = process.env.OPENAI_API_KEY;
const { Configuration, OpenAIApi } = require("openai");
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
const response = await openai.listModels();
console.log(response.data);
OpenAI 提供的语言模型
| Model Name | Used for | Cost |
|---|---|---|
gpt-4/gpt-4-0613 | General purpose | $0.03 per 1,000 tokens for input, $0.06 per 1,000 tokens for output |
gpt-3.5-turbo/gpt-3.5-turbo-0613 | General purpose | 0.0015 per 1,000 tokens for input, $0.003 per 1,000 tokens for output |
ada | Embeddings | $0.0001 per 1,000 tokens |
详细价格查询 https://openai.com/pricing
如何计算文本的 Token?
基本概念
- Token: 是一种自然语言处理中文本的基本单位,例如:
What is your name?有 5 个 Token,分别是What,is,your,name,?。 - Tokenization: 是一种将文本转换为 Token 的过程,例如:
What is your name?会被转换为What,is,your,name,?。转换后的 Token 可以被计算机更好的理解。
Token的数量一般与模型的计算量成正比,Token 越多,模型计算量越大,模型的计算时间越长,模型的计算费用越高。 因此大部分语言模型都会以 Token 为单位计算费用。
使用 OpenAI API 进行 Tokenization
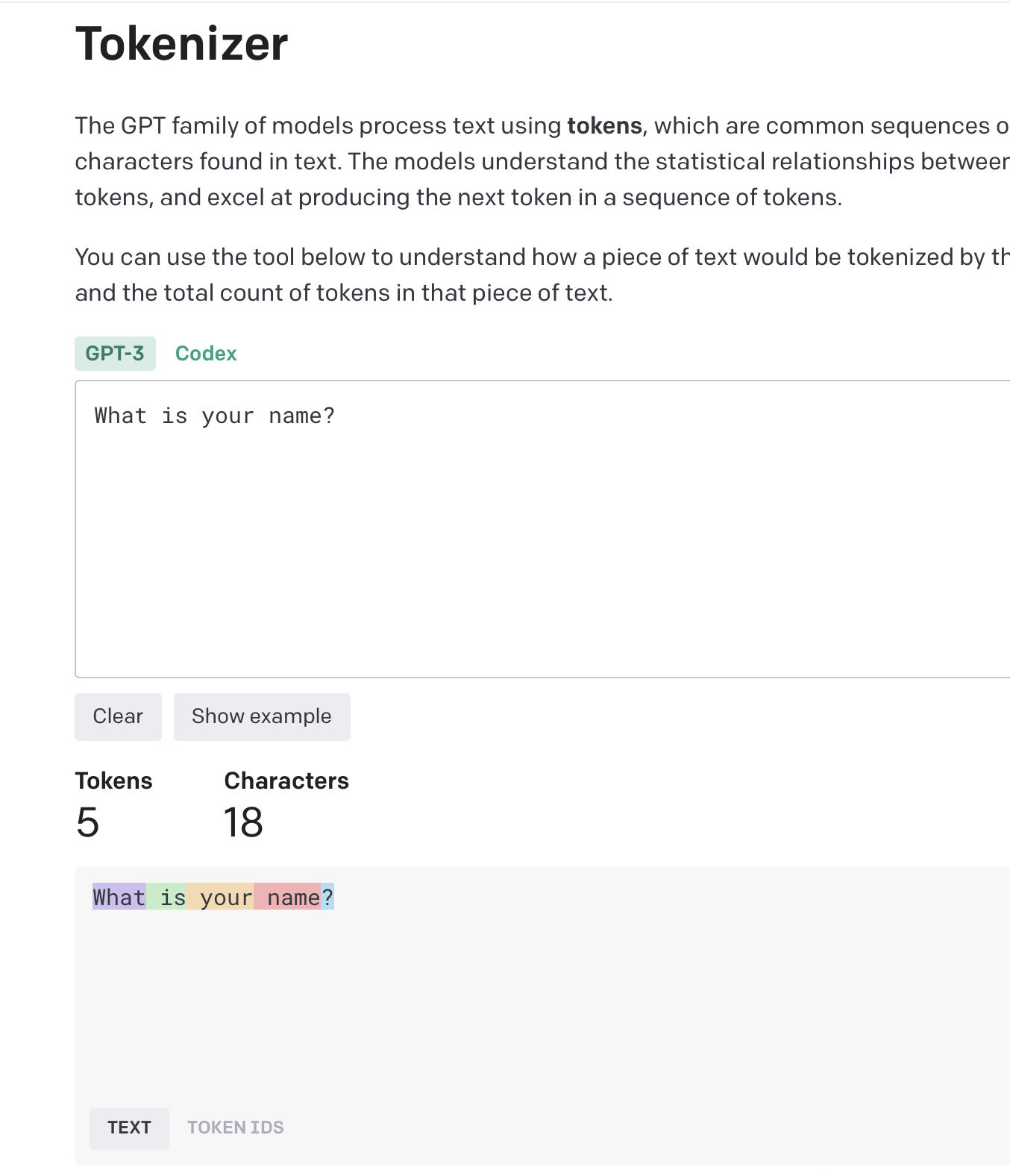
Token 估算token
1 token ~= 4 chars in English
1 token ~= ¾ words
100 tokens ~= 75 words
Or
1-2 sentence ~= 30 tokens
1 paragraph ~= 100 tokens
1,500 words ~= 2048 tokens
语言模型的 Token 上限
- 上限为 2048 个 Token,超过 2048 个 Token 会被截断。(不同的模型上限不同,例如:
gpt-3.5-turbo上限为 2048 个 Token,ada上限为 1024 个 Token) - 上限包括输入和输出的 Token,例如:输入 1000 个 Token,输出 1000 个 Token,那么总共 2000 个 Token,不会被截断。
gpt-3.5-turbo-16k,gpt-3.5-turbo-0613模型的上限为 16,384 个 Token。gpt-4-32k,gpt-4-32k-0613模型的上限为 32,768 个 Token。
Open AI 提示词工程与进阶使用prompt-engineering
如何设定 ChatGPT API 函数参数?
基本概念
- role: 是对话中的角色,例如:
user是用户,system是系统,assistant是对话机器人。 - role:system: 它非必需的设定,但是可以帮助模型更好的理解对话的角色,例如:
You are a helpful assistant.。可以理解为机器人的「人设」。 - content: 是对话中的内容,例如:
墨尔本位于哪个国家?。 - temperature: 是对话中的温度,例如:
1.0。介于0到2之间,值越大,生成的内容越随机(创造性),值越小,生成的内容越保守(可信度)。 - top_p: 用于替代
temperature的采样参数。设定候选词的最低累积概率,例如:0.9。介于0到1之间,值越大,生成的内容越随机(创造性),值越小,生成的内容越保守(可信度)。
role / system 的使用
require('dotenv').config(); // 引入 dotenv 模块,同时加载 .env 文件中的环境变量(即 API KEY)
const OPENAI_API_KEY = process.env.OPENAI_API_KEY;
const { Configuration, OpenAIApi } = require("openai");
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
// default value
// {role: "system", content: "You are a helpful assistant."},
{role: "user", content: "澳大利亚哪个城市最好?"}],
});
console.log(completion.data.choices[0].message);
例子一:
completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{role: "system", content: "You are a rapper."},
{role: "user", content: "澳大利亚哪个城市最好?"}],
});
console.log(completion.data.choices[0].message);
例子二:
completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{role: "system", content: "你是一名幼儿园教师,正在回答5岁儿童的问题."},
{role: "user", content: "澳大利亚哪个城市最好?"}],
});
console.log(completion.data.choices[0].message);
如何让 ChatGPT 保留上下文记忆?
重要概念:
- 上下文记忆:是指 ChatGPT 在对话中记住上一次对话的内容,从而生成更加符合上下文的回复。这对于处理复杂的对话非常重要。管理上下文记忆的方法有很多,本课程介绍的通过将历史对话的内容作为输入,从而让 ChatGPT 保留上下文记忆。这个方法受限于模型的 Token 上限,因此只能保留有限的上下文记忆。
默认情况下,通过API 调用 ChatGPT 时,每次都会重新开始对话,不会保留上下文记忆。例如:
completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{role: "user", content: "我刚刚说过什么?"}],
});
console.log(completion.data.choices[0].message);
输出:
{ role: 'assistant', content: '根据对话的上下文,我无法判断您刚刚说过什么。请提供更多信息。' }
如果想要保留上下文记忆,需要在每次对话时,将上一次对话的内容作为输入。
completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{role: "user", content: "墨尔本位于哪个国家?"},
],
});
console.log(completion.data.choices[0].message);
语言模型会返回内容
{ role: 'assistant', content: '墨尔本位于澳大利亚。' }
然后将上一次对话的内容作为输入,再次调用API。
completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{role: "user", content: "墨尔本位于哪个国家?"},
{role: "assistant", content: "墨尔本位于澳大利亚。"},
{role: "user", content: "这个国家的首都是哪里?"},
],
});
console.log(completion.data.choices[0].message);
语言模型会返回内容
{ role: 'assistant', content: '澳大利亚的首都是堪培拉。' }
如何给 ChatGPT 撰写更好的Prompt提示词? openai-prompt-engineering
官方建议6大策略:
1. 写清楚的指示(Write clear instructions )
1.1. 提供尽可能多问题的细节
- 反面例子:
Summarize the meeting notes. - 正面例子:
Summarize the meeting notes in a single paragraph. Then write a markdown list of the speakers and each of their key points. Finally, list the next steps or action items suggested by the speakers, if any
1.2 给模型一个人物设定(Ask the model to adopt a persona)
例如:
{role: "system", content: "你是一名幼儿园教师,正在回答5岁儿童的问题."},
1.3 使用分隔符明确指示输入的不同部分(Use delimiters to clearly indicate distinct parts of the input)
Summarize the text delimited by triple quotes with a haiku.
"""insert text here"""
1.4 按顺序指定完成任务所需的步骤(Specify the steps required to complete a task)
Use the following step-by-step instructions to respond to user inputs.
Step 1 - The user will provide you with text in triple quotes. Summarize this text in one sentence with a prefix that says "Summary: ".
Step 2 - Translate the summary from Step 1 into Spanish, with a prefix that says "Translation: ".
1.5 使用示例(Use examples)
[
{role: "system", content: "Answer in a consistent style."},
{role: "user", content: "Teach me about patience"},
{role: "assistant", content: "The river that carves the deepest valley flows from a modest spring; the grandest symphony originates from a single note; the most intricate tapestry begins with a solitary thread."},
{role: "user", content: "Teach me about the ocean"},
]
1.6 指定输出的期望长度(Specify the desired length of the output)
Summarize the text delimited by triple quotes in about 50 words.
"""insert text here"""
2.提供参考文本 ( Provide reference text )
2.1 指示模型使用参考文本回答 (Instruct the model to answer using a reference text)
Use the provided articles delimited by triple quotes to answer questions. If the answer cannot be found in the articles, write "I could not find an answer."
2.2 指示模型使用参考文本引用回答 (Instruct the model to answer with citations from a reference text)
You will be provided with a document delimited by triple quotes and a question. Your task is to answer the question using only the provided document and to cite the passage(s) of the document used to answer the question. If the document does not contain the information needed to answer this question then simply write: "Insufficient information." If an answer to the question is provided, it must be annotated with a citation. Use the following format for to cite relevant passages ({"citation": …}).
3. 将复杂的任务分解为简单的子任务 (Split complex tasks into simpler subtasks)
3.1 使用意图分类来识别用户查询的最相关的指令 (Use intent classification to identify the most relevant instructions for a user query)
You will be provided with customer service inquiries that require troubleshooting in a technical support context. Help the user by:
- Ask them to check that all cables to/from the router are connected. Note that it is common for cables to come loose over time.
- If all cables are connected and the issue persists, ask them which router model they are using
- Now you will advise them how to restart their device:
-- If the model number is MTD-327J, advise them to push the red button and hold it for 5 seconds, then wait 5 minutes before testing the connection.
-- If the model number is MTD-327S, advise them to unplug and replug it, then wait 5 minutes before testing the connection.
- If the customer's issue persists after restarting the device and waiting 5 minutes, connect them to IT support by outputting {"IT support requested"}.
- If the user starts asking questions that are unrelated to this topic then confirm if they would like to end the current chat about troubleshooting and classify their request according to the following scheme:
...
4.2 对于需要非常长的对话的对话应用程序,请总结或过滤以前的对话 (For dialogue applications that require very long conversations, summarize or filter previous dialogue)
- 一旦对话达到一定长度,就要求模型总结对话的内容,以压缩对话的长度。
- 亦可使用基于embedding的相似度度量,检索相关的对话
4.3 递归地分段总结长文档 (Summarize long documents piecewise and construct a full summary recursively)summarizing-books
针对长文档:
- 先逐个小节(section)进行总结
- 多个小节的总结再进行总结
- 直到最终得到整个文档的总结
4. 给GPTs一些时间来“思考” (Give GPTs time to "think" )
参考 思维链的内容
4.1 让模型在得出结论之前先想出自己的解决方案 (Instruct the model to work out its own solution before rushing to a conclusion )
First work out your own solution to the problem. Then compare your solution to the student's solution and evaluate if the student's solution is correct or not. Don't decide if the student's solution is correct until you have done the problem yourself
4.2 使用内心独白或一系列查询来隐藏模型的推理过程 (Use inner monologue or a sequence of queries to hide the model's reasoning process)
- 目的:在给出正确回答的同时,隐藏推理过程
5. 使用外部工具 (Use external tools )
5.1 使用基于嵌入的搜索来实现高效的知识检索 (Use embeddings-based search to implement efficient knowledge retrieval)
参考 如何使用 OpenAI 进行文本向量化(embedding)?的内容
5.2 使用代码执行或调用外部API来执行更准确的计算 (Use code execution to perform more accurate calculations or call external APIs)
You can write and execute Python code by enclosing it in triple backticks, e.g. ```code goes here```. Use this to perform calculations.
5.3 给模型访问特定函数的权限 (Give the model access to specific functions)
参考 函数调用的内容
6.系统地测试变化( Test changes systematically )
当优化我们的提示词时,或者OpenAI发布了新的模型时,我们的应用的性能可能会发生变化。 我们需要进行系统的测试,以确保我们的应用程序仍然按预期工作。
6.1 使用参考答案评估模型输出(Evaluate model outputs with reference to gold-standard answers)
用模型的输出与标准答案进行比较,以评估模型的性能。 评估本身也是通过GPT语言模型完成的。
You will be provided with text delimited by triple quotes that is supposed to be the answer to a question. Check if the following pieces of information are directly contained in the answer:
- Neil Armstrong was the first person to walk on the moon.
- The date Neil Armstrong first walked on the moon was July 21, 1969.
For each of these points perform the following steps:
1 - Restate the point.
2 - Provide a citation from the answer which is closest to this point.
3 - Consider if someone reading the citation who doesn't know the topic could directly infer the point. Explain why or why not before making up your mind.
4 - Write "yes" if the answer to 3 was yes, otherwise write "no".
Finally, provide a count of how many "yes" answers there are. Provide this count as {"count": <insert count here>}.
如何使用 思维链 (Chain of Thought)帮助模型处理复杂的问题?chain-of-thought
- LLM 通常在推理时表现不佳
- 使用大模型时,要求LLM先做一步一步的推演,然后再回答问题,会得到更好的结果
- 原理是:语言模型的结果生成时token by token的,所以在生成结果前,都可以做一次推演,会引入更多的计算和“思考”,这样就可以得到更好的结果
反面例子:
计算24点是一个数学游戏,目标是通过使用给定的四个数字,通过加减乘除等基本运算符号,计算得到结果为24,你的答案是一个数字和符号组成的计算公式
你现在拿到的数字是:1,2,3,4
使用思维链的例子:
计算24点是一个数学游戏,目标是通过使用给定的四个数字,通过加减乘除等基本运算符号,计算得到结果为24,你的答案是一个数字和符号组成的计算公式
你现在拿到的数字是:1,2,3,4
请列出你的思考步骤,再给出最终答案
反面例子2:
在这些数字中1,3,5,23,69,70,10,84,923,32有多少个奇数,多少个偶数。
使用思维链的例子2:
在这些数字中1,3,5,23,69,70,10,84,923,32有多少个奇数,多少个偶数。
请列出你的思考步骤,再给出最终答案
请注意: 网页版的 ChatGPT 对话能力进行过优化,可能已经具备了思维链的能力。该技巧适合没有针对思维链进行优化的模型。
如何使用 少样本学习 (Few Shot)的到自己想要的结果?
基本概念
- 少样本学习(Few Shot): 是一种通过给模型提供少量样本,从而让模型学习到更多知识的方法。例如:给模型提供少量的样本,让模型学习到如何回答问题,从而让模型回答更多的问题。与之相关的概念是零样本学习(Zero Shot)
- 零样本学习(Zero Shot): 模型在没有任何样本的情况下,就可以回答问题。
零样本学习(Zero Shot)的例子:
韩国的首都是
少样本学习的例子:
中国的首都是北京,北京有天安门,故宫,长城等著名景点。
日本的首都是东京,东京有东京塔,浅草寺,秋叶原等著名景点。
法国的首都是巴黎,巴黎有埃菲尔铁塔、卢浮宫、巴黎圣母院等著名景点。
韩国的首都是
如何 OpenAI 的对话中进行函数调用?openai-chat-function
基本概念
- function(函数): 可以执行特定任务的代码块,例如:
get_current_weather(location)可以获取指定位置location的当前天气。 - function call(函数调用): 是对函数的调用,例如:
get_current_weather("Melbourne")即可获取墨尔本的当前天气。 - OpenAI 对话API中的函数调用: 允许用户在对话中向语言模型提供函数调用,并允许模型执行函数调用并返回结果。
例子
completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{role: "user", content: "今天天气怎么样?"}],
});
console.log(completion.data.choices[0].message);
{
role: 'assistant',
content: '很抱歉,我无法提供实时天气信息,请您自行查阅天气预报或者使用天气类的应用程序来获取。'
}
重新提问,并告诉模型如何调用天气函数:
completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{role: "user", content: "今天天气怎么样?"}],
functions: [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
]
});
console.log(completion.data.choices[0].message);
模型返回结果要求进行函数调用:
{
role: 'assistant',
content: null,
function_call: {
name: 'get_current_weather',
arguments: '{\n "location": "北京"\n}'
}
}
假设我们运行get_current_weather函数并得到结果
{ "temperature": 22, "unit": "celsius", "description": "Sunny" }
那么我们可以将结果传递给模型:
completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{role: "user", content: "今天天气怎么样?"},
{
role: 'assistant',
content: null,
function_call: {
name: 'get_current_weather',
arguments: '{\n "location": "北京"\n}'
}
},
{
role: "function",
name: "get_current_weather",
content: "{\"temperature\": \"22\", \"unit\": \"celsius\", \"description\": \"Sunny\"}"
}
], functions: [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
},
]});
console.log(completion.data.choices[0].message);
返回结果
{
role: 'assistant',
content: '今天北京的天气很好,温度为22摄氏度,阳光明媚。'
}
Under the hood, functions are injected into the system message in a syntax the model has been trained on. This means functions count against the model's context limit and are billed as input tokens. If running into context limits, we suggest limiting the number of functions or the length of documentation you provide for function parameters
Open AI 的其他模型
如何使用 OpenAI 进行文本补全?chat-completion
基本概念
- 文本补全: 是指给定一段文本,模型会根据文本的上下文,生成下一个最可能的词或短语。用于给定主题的文章编写、代码片段的解读。例如生成自动回复、自动摘要、文本扩充等方面的应用。
模型选择:text-davinci-003 性能最强(贵),text-ada-001 便宜且块(性能一般)completion_models
注意:completions 逐步被Chat Completion取代
require('dotenv').config(); // 引入 dotenv 模块,同时加载 .env 文件中的环境变量(即 API KEY)
const OPENAI_API_KEY = process.env.OPENAI_API_KEY;
const { Configuration, OpenAIApi } = require("openai");
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
// Request completion
completion = await openai.createCompletion(
{
model: "text-davinci-003",
prompt: "Once upon a time, there was a princess who",
},
{
maxTokens: 5,
}
);
console.log(completion.data.choices[0].text);
如何使用 OpenAI 进行文本向量化(embedding)?
什么是embedding what-are-embeddings: 文本向量化(embedding)是将文本转换为数值向量的过程。转换后的向量可以被计算机更好的理解。在大语言模型以前,常用的embedding方法是word2vec,TF-IDF,bag-of-words等
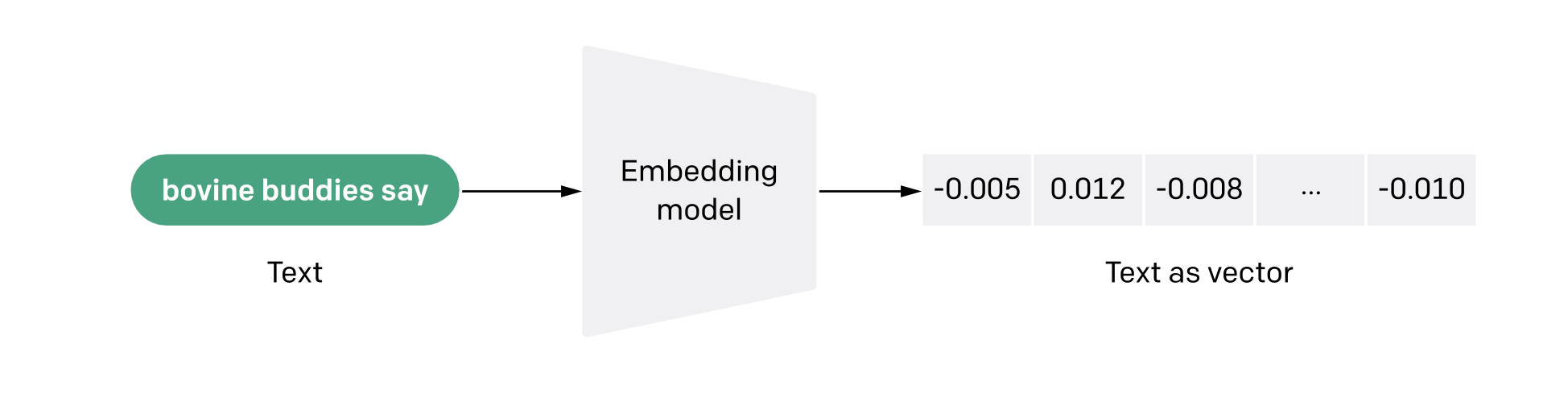
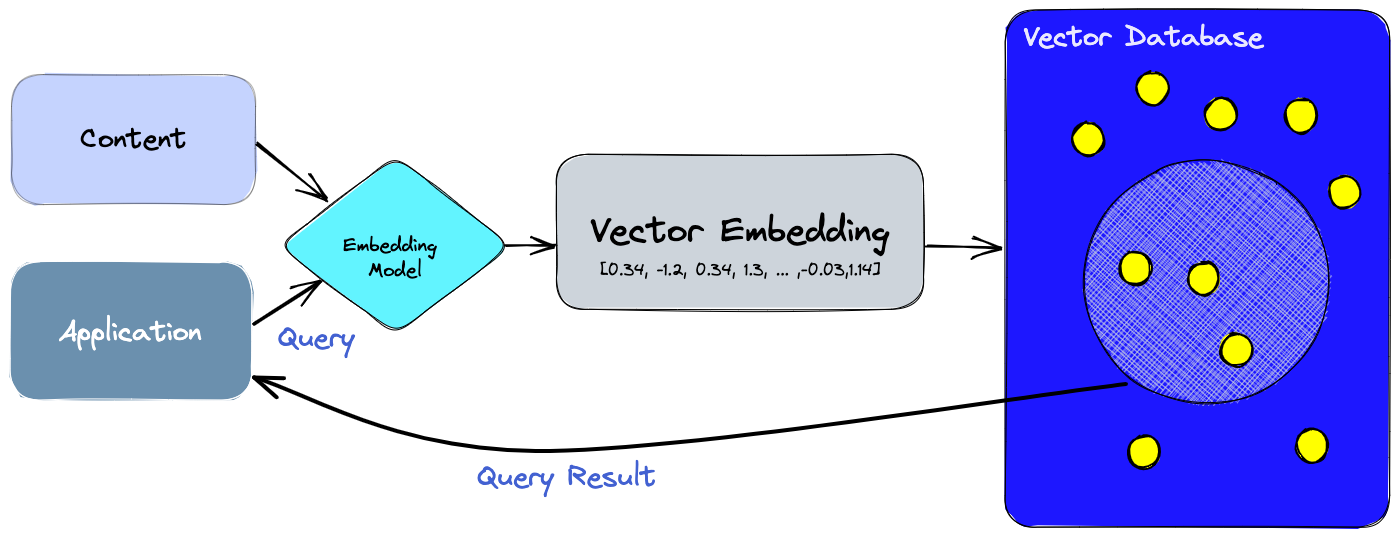
为什么要Embedding?: 可以用于计算文本之间的相似度,例如:计算两个文本的cos相似度。
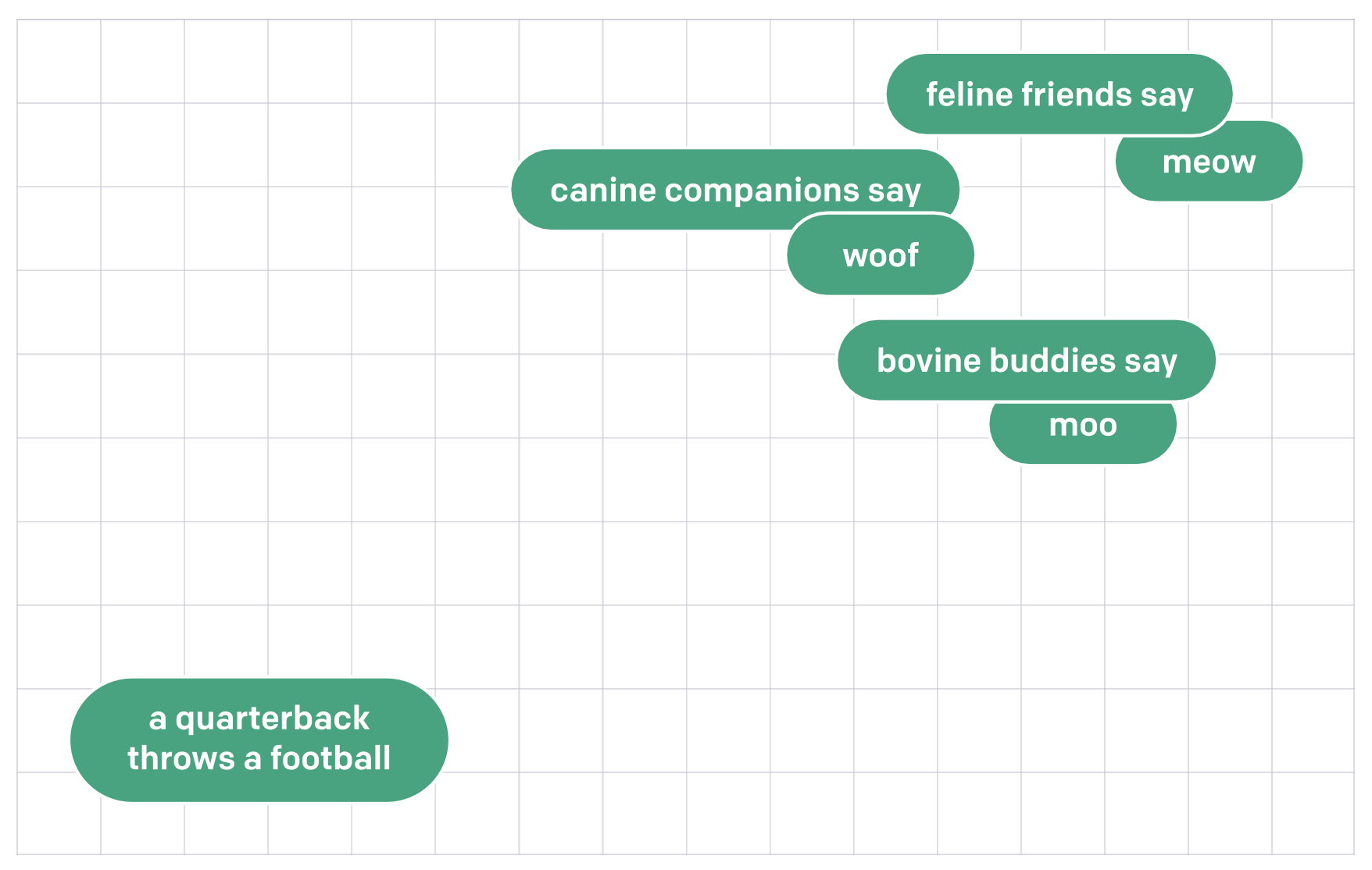
words = ["White House", "Car", "school", "student", "pencil"],
// Request embedding
embedding = await openai.createEmbedding(
{
model: "text-embedding-ada-002",
input: words,
}
);
console.log(embedding.data);
得到文本转换成向量的结果
for (var i = 0; i < embedding.data.data.length; i++) {
// only show the first 4 elements of the embedding
console.log(words[i] + ": " + embedding.data.data[i].embedding.slice(0, 4) + "...");
}
White House: -0.02824106,-0.012833937,-0.013992512,-0.006442572...
Car: -0.004937784,-0.0123615805,-0.0044446904,-0.020627746...
school: 0.0019221164,0.001822042,-0.0026226363,-0.019214261...
student: -0.002566315,-0.006891411,0.0070761857,-0.020872695...
pencil: -0.00972931,0.0031284764,0.011547685,-0.019445201...
重要概念
- 文本相似度: 是指两个文本之间的相似程度。例如:king 和 queen 的相似度很高,king 和 car 的相似度很低。
- 文本相似度的度量: 一般使用cos相似度来度量文本之间的相似度。cos相似度的取值范围是[-1, 1],值越大。除了cos相似度,还有其他的相似度度量方法,例如:欧式距离、曼哈顿距离等。
- 余弦相似度(cosine similarity): 是指两个向量之间的夹角的余弦值。余弦值越大,两个向量越相似。余弦值越小,两个向量越不相似。余弦值为1时,两个向量完全相同;余弦值为-1时,两个向量完全相反;余弦值为0时,两个向量互不相关。计算公式是:
计算cos相似度
embedding_list = embedding.data.data
for (var i = 0; i < embedding_list.length; i++) {
for (var j = i+1; j < embedding_list.length; j++) {
if (i != j) {
var similarity = 0;
var norm_i = 0;
var norm_j = 0;
for (var k = 0; k < embedding_list[i].embedding.length; k++) {
similarity += embedding_list[i].embedding[k] * embedding_list[j].embedding[k];
norm_i += embedding_list[i].embedding[k] * embedding_list[i].embedding[k];
norm_j += embedding_list[j].embedding[k] * embedding_list[j].embedding[k];
}
similarity = similarity / Math.sqrt(norm_i) / Math.sqrt(norm_j);
console.log("Similarity between " + words[i] + " and " + words[j] + ": " + similarity);
}
}
}
得到文本之间的相似度
Similarity between White House and Car: 0.7776689810472857
Similarity between White House and school: 0.8067059932289337
Similarity between White House and student: 0.7718342820389198
Similarity between White House and pencil: 0.7861272227316457
Similarity between Car and school: 0.8231716745408062
Similarity between Car and student: 0.8186800886544682
Similarity between Car and pencil: 0.7841093504081722
Similarity between school and student: 0.9181619919402767
Similarity between school and pencil: 0.8117307201698494
Similarity between student and pencil: 0.8085630014757886
如何使用 OpenAI 进行文本审查?openai-moderation
基本概念
- 文本审查(moderation): 是指对文本进行过滤,例如:过滤色情、暴力、仇恨等内容。
moderation = await openai.createModeration({
input: "唯小人与女子为难养也"
});
console.log(moderation.data);
console.log(moderation.data.results[0].categories);
console.log(moderation.data.results[0].category_scores);
审查结果判定为 harassment 内容
{
sexual: false,
hate: false,
harassment: true, // <---
'self-harm': false,
'sexual/minors': false,
'hate/threatening': false,
'violence/graphic': false,
'self-harm/intent': false,
'self-harm/instructions': false,
'harassment/threatening': false,
violence: false
}
{
sexual: 0.017712448,
hate: 0.13545704,
harassment: 0.43109462,
'self-harm': 0.000048899128,
'sexual/minors': 0.0016177263,
'hate/threatening': 0.000018300225,
'violence/graphic': 0.000043072254,
'self-harm/intent': 0.000037665995,
'self-harm/instructions': 0.000033658653,
'harassment/threatening': 0.0036699886,
violence: 0.002088313
}
moderation = await openai.createModeration({
input: "如何伤害自己"
});
console.log(moderation.data);
console.log(moderation.data.results[0].categories);
console.log(moderation.data.results[0].category_scores);
得到以下内容
> console.log(moderation.data);
{
id: 'modr-7eLLYpM8y7i0xDTkvRlXtt6RoliEl',
model: 'text-moderation-005',
results: [
{ flagged: true, categories: [Object], category_scores: [Object] }
]
}
> console.log(moderation.data.results[0].categories);
{
sexual: false,
hate: false,
harassment: false,
'self-harm': true, // <=====
'sexual/minors': false,
'hate/threatening': false,
'violence/graphic': false,
'self-harm/intent': false,
'self-harm/instructions': false,
'harassment/threatening': false,
violence: false
}
> console.log(moderation.data.results[0].category_scores);
{
sexual: 0.0012696498,
hate: 0.0000010119785,
harassment: 0.0010820183,
'self-harm': 0.3130136, // <=====
'sexual/minors': 0.000044632907,
'hate/threatening': 0.000008675129,
'violence/graphic': 0.0008116822,
'self-harm/intent': 0.12645212,
'self-harm/instructions': 0.004748119,
'harassment/threatening': 0.002073936,
violence: 0.23937659
}
如何使用 OpenAI API 进行图片生成?
基本概念
- 图像生成: 是指根据给定的文本,生成对应的图像。例如:给定一段文本,生成对应的图像。
- 图像编辑: 是指根据给定的图像和文本,和掩膜图像(mask image),对图像的某些部分进行编辑
- 图像变种(Image Variations): 是指根据给定的图像,生成类似的图像,但是有一些变化。例如:给定一张猫的图像,生成类似的猫的图像,但是有一些变化。
图像生成
require('dotenv').config(); // 读取本地.env 文件
const OPENAI_API_KEY = process.env.OPENAI_API_KEY;
const { Configuration, OpenAIApi } = require("openai");
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
/************ 图像生成 ************/
response = await openai.createImage({
prompt: "a white siamese cat",
n: 1,
size: "1024x1024",
});
image_url = response.data.data[0].url;
console.log(image_url);
得到图像

图像编辑
原始图像

掩膜图像

response = await openai.createImageEdit(
fs.createReadStream("image_edit_original.png"),
"A sunlit indoor lounge area with a pool containing a large yellow Pikachu",
fs.createReadStream("image_edit_mask.png"),
1,
"1024x1024"
).catch((error) => {
console.log(error.response.data);
});
image_url = response.data.data[0].url;
console.log(image_url);
编辑后的图像

图像变种(Image Variations)
输入图像
response = await openai.createImageVariation(
fs.createReadStream("white-cat.png"),
1,
"1024x1024"
).catch((error) => {
console.log(error.response.data);
});
image_url = response.data.data[0].url;
console.log(image_url);
变种图像

适用于对于图像整体满意,但是想要一些变化的场景
如何使用 OpenAI API 语音转录文字open-speech-to-text
基本概念
- 语音转录文字: 是指将语音转换为文字。例如:将录音转换为文字。
- Whisper: 是OpenAI的语音转录文字模型,目前只有一个模型可用,名称为
whisper-1,支持超过40种语言,详见whisper-languages。这是一个开源模型,可以在OpenAI的GitHub上找到。
使用方法
resp = await openai.createTranscription(
fs.createReadStream("demo.m4a"),
"whisper-1"
);
console.log(resp.data);
参数说明:
model=whisper-1:模型名称,目前只有一个模型可用prompt: An optional text to guide the model's style or continue a previous audio segment. The prompt should match the audio language, 可选参数,用于指导模型的风格或者继续之前的音频片段,prompt的语言应该和音频的语言一致response_format: 可选参数,输出的格式,json, text, srt, verbose_json, or vtt,默认为jsontemperature: 采样温度,介于0和1之间,值越大,输出越随机,值越小,输出越集中和确定性。如果设置为0,模型将使用对数概率(log probability)自动增加温度,直到达到某些阈值。language: 语言,目前支持超过40+种语言,详见whisper-languages
开源模型
为什么要使用开源模型?
- 隐私考虑: 你的数据不会离开你的服务器,不会被上传到云端。特别是对于一些敏感的数据,例如医疗数据,金融数据,政府数据等,不会被上传到云端,不会被泄露。
- 成本考虑: AIaaS(AI as a Service)按照使用量计费,如果你的应用有大量的用户,那么成本会很高。而使用开源模型,你只需要在自己的服务器上运行,成本会低很多。
- 可控性: 可以使用自己的私域数据进行模型微调,使得模型更加适合自己的应用场景。
如何获取开源模型?
常见开源模型分享站:
- Huggingface: 最大的开源模型分享站,包含了各种各样的模型,包括NLP,CV,语音等
- Paper with Code:学术界最大的模型分享站,专注于模型的评测
- TF Hub:TensorFlow官方的模型分享站
- Model Garden for TensorFlow:TensorFlow官方的模型分享站
如何在Huggingface中搜索开源模型?
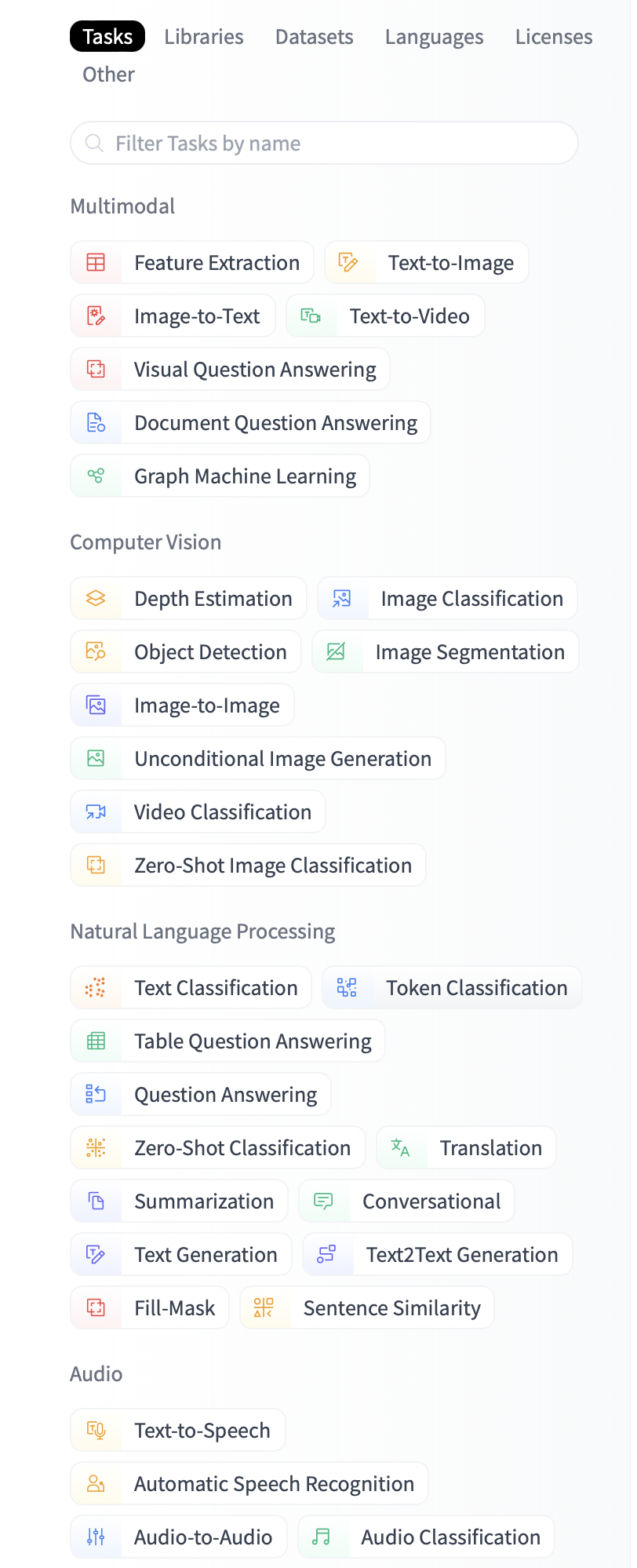
- 在Huggingface的模型搜索页面中搜索
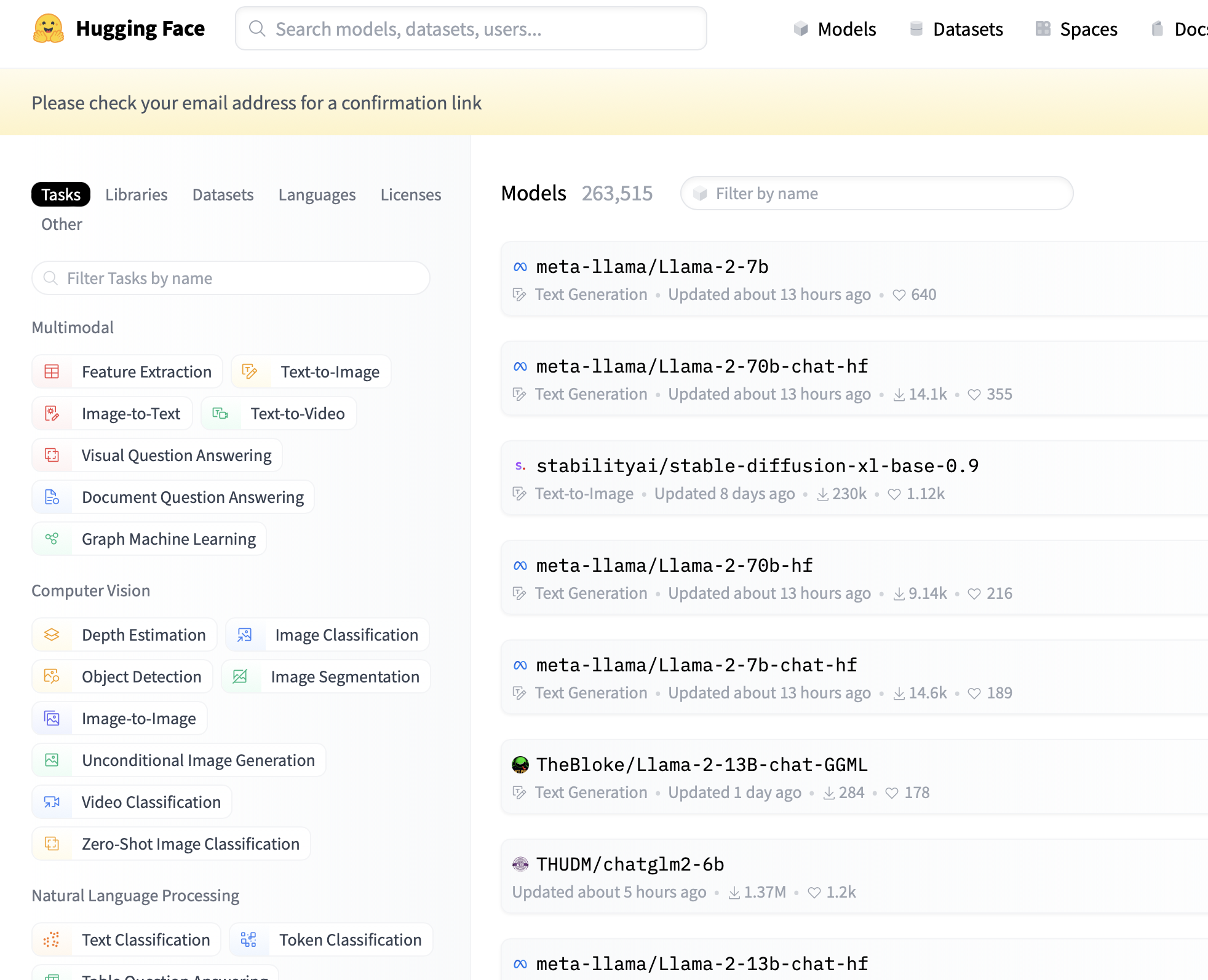
- 根据 Task 类型搜索需要的模型
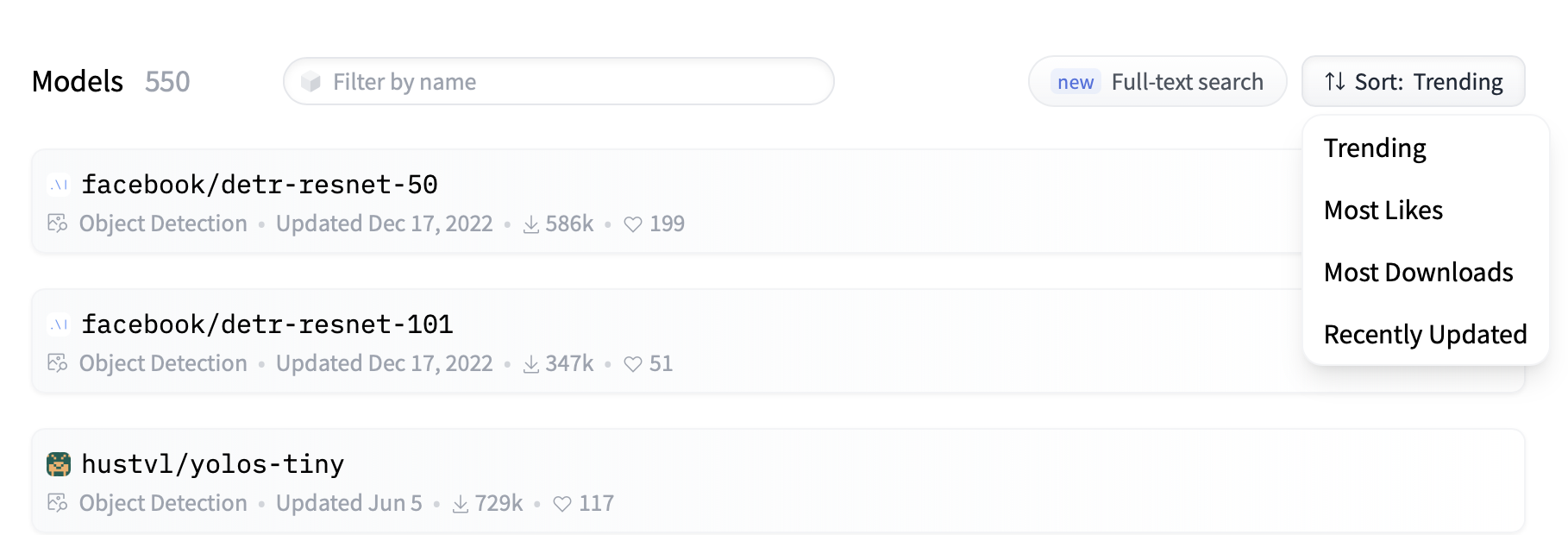
- 可以按照模型的属性进行排序
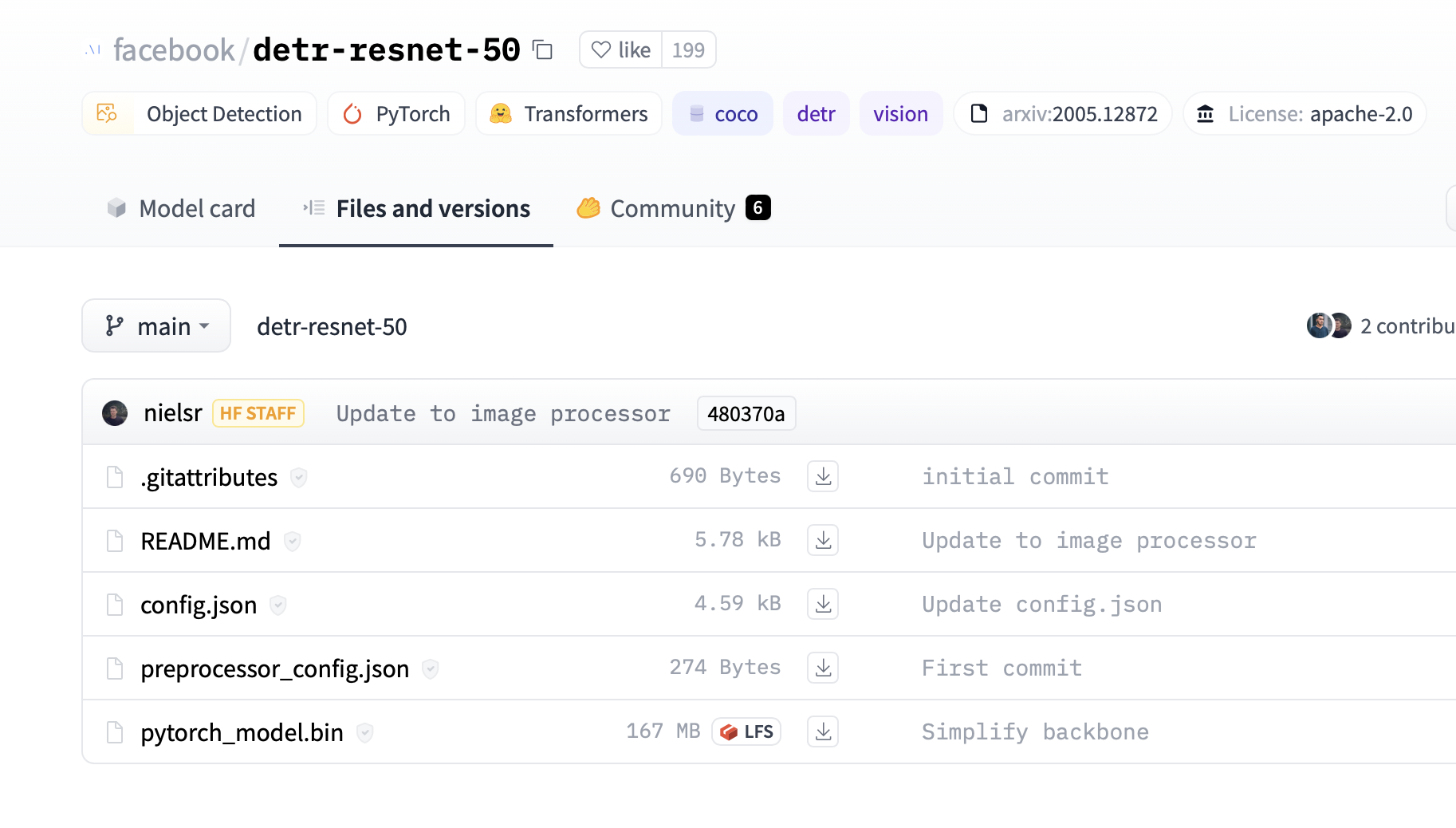
- 注意模型的大小,模型越大,需要的内存和计算资源越多
如何在自己的Node.js项目中使用开源模型?hugging-face-nodejs
检查node版本
node -v
需要node版本大于18才能正常使用
npm init -y
npm install @xenova/transformers
let { pipeline, env } = await import('@xenova/transformers');
let classifier = await pipeline("text-classification", "Xenova/distilbert-base-uncased-finetuned-sst-2-english");
text = "Hello world!!!!";
response = await classifier(text);
text = "I am not happy";
response = await classifier(text);
得到结果
> response = await classifier(text);
[ { label: 'POSITIVE', score: 0.9998103976249695 } ]
> text = "I am not happy";
'I am not happy'
> response = await classifier(text);
[ { label: 'NEGATIVE', score: 0.9997795224189758 } ]
如何使用开源模型完成翻译任务?
let { pipeline, env } = await import('@xenova/transformers');
translator = await pipeline("translation", "Xenova/nllb-200-distilled-600M");
text = "Sunny Day";
response = await translator(
text, {
"src_lang": "eng_Latn",
"tgt_lang": "zho_Hans"
}
);
得到结果
console.log(response);
[ { translation_text: '晴天' } ]
使用场景:
多语言翻译: 例如将英语翻译成中文,将中文翻译成英文等
如何使用开源模型完成文本摘要任务?
概念介绍:
- 文本摘要: 将一篇长文档,通过提取关键信息,生成一篇短文档,用于快速了解文档的内容,例如:新闻摘要,文档摘要等
- 文本摘要模型: 用于生成文本摘要的模型,例如:BART,T5,PEGASUS等
- BART模型: 由Facebook AI Research开发的一种序列到序列的模型,用于生成文本摘要,翻译,问答等任务
- distilbart: 在Bart模型的基础上进行了压缩,模型尺寸减小,速度更快,但是性能略有下降
let { pipeline, env } = await import('@xenova/transformers');
summarizer = await pipeline("summarization", "Xenova/distilbart-cnn-6-6");
text = "The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft). Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct.";
response = await summarizer(text, { "min_length": 30, "max_length": 100 });
console.log(response);
得到结果
[ { summary_text: 'The Eiffel Tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side.' } ]
如何使用开源的问答模型?
let { pipeline, env } = await import('@xenova/transformers');
text_generator = await pipeline("text-generation", "Xenova/LaMini-GPT-124M");
input_prompt = '### Question:\n' +
' Please let me know your thoughts on the given place and why you think it deserves to be visited: "Melbourne, Australia"\n' +
'\n' +
'### Response:\n';
response = await text_generator(input_prompt, { "max_length": 800, do_sample: true, "temperature": 0.5 });
console.log(response);
运行结果
> console.log(response);
[
{
generated_text: '### Question:\n' +
' Please let me know your thoughts on the given place and why you think it deserves to be visited: "Melbourne, Australia"\n' +
'\n' +
'### Response:\n' +
'The Melbourne, Australia location is a popular tourist destination, and it is a popular tourist destination due to its proximity to the Australian capital and its unique history and culture. However, the city is also home to several popular tourist attractions such as the Sydney Opera House and the Warraschen Museum.'
}
]
注意事项
- 目前的开源模型,相比ChatGPT性能较差,只适合进行简单的问答,或者进行 few-shot learning
- 如果需要更好的性能,可以使用更大的模型,例如:GPT-Neo,GPT-J,Llama等
input_prompt = '## Context \n' +
'we are trying to classify the following text\'s sentiment. \n' +
'Possible sentiments are: Positive, Negative, Neutral \n' +
'\n' +
'### Text: \n' +
'The movie was really good. I enjoyed watching it very much. \n' +
'\n' +
'### Sentiment is: \n' +
'{\'sentiment\':';
response = await text_generator(input_prompt, { "max_length": 800, do_sample: true, "temperature": 0.2 });
console.log(response);
得到结果
> console.log(response);
[
{
generated_text: '## Context \n' +
"we are trying to classify the following text's sentiment. \n" +
'Possible sentiments are: Positive, Negative, Neutral \n' +
'### Text: \n' +
'The movie was really good. I enjoyed watching it very much. \n' +
'### Sentiment is: \n' +
"{'sentiment': 'positive', 'neutral': 'I enjoyed watching it very much.'}"
}
]
产品、运维与生产实践
LLM 通常用于什么场景?
- 通用场景:例如:文本摘要,文本生成等
- 特殊场景:
- 垂直领域机器人 (Niche chatbots)
- 客服机器人(Customer support bots)
- 代码自动补全(Code autocompletion):Github Copilot, SQL (Databricks AI)
- 数据增强(data enrichment)
- 数据标签(data labeling)
- 合成数据生成 (synthetic data creation)
- SME 问题生成(SME question generation)
LLM 在生产中使用有什么问题?
- 幻觉(Hallucination):LLM会生成一些不合理的内容,对于关键任务,这些内容可能会导致严重的后果
- 性能问题:LLM的推理速度相对较慢,对于低延迟、实时性要求较高的场景,LLM可能无法满足要求
- Prompt工程:LLM的性能依赖于Prompt的设计,但最好的prompt也不能保证正确性,LLM的输出还有一定的随机性
- 不清晰的ROI: LLM的费用及其带来的价值不稳定,很难计算ROI
参考资料:
- https://agi-talks.vercel.app/101-prompt-engineering
- https://agi-talks.vercel.app/102-openai-api
- https://github.com/datawhalechina/prompt-engineering-for-developers
- https://github.com/openai/openai-cookbook
- https://github.com/webup/agi-talks
- https://ywh1bkansf.feishu.cn/wiki/Q5mXww4rriujFFkFQOzc8uIsnah?table=tbldSgFt2xNUDNAz&view=vewo2g2ktO
- https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them↩
- https://www.deeplearning.ai/the-batch/how-prompting-is-changing-machine-learning-development↩
- https://platform.openai.com/docs/guides/gpt-best-practices/strategy-write-clear-instructions↩
- Summarizing Books: https://openai.com/research/summarizing-books↩
- Chain of Thought: https://www.youtube.com/watch?v=H4J59iG3t5o↩
- https://openai.com/blog/function-calling-and-other-api-updates↩
- https://platform.openai.com/docs/guides/gpt/chat-completions-vs-completions↩
- https://platform.openai.com/docs/api-reference/completions/create↩
- https://platform.openai.com/docs/guides/embeddings/what-are-embeddings and https://openai.com/blog/introducing-text-and-code-embeddings↩
- https://platform.openai.com/docs/guides/moderation↩
- https://platform.openai.com/docs/guides/speech-to-text↩
- https://github.com/openai/whisper#available-models-and-languages↩
- https://huggingface.co/docs/transformers.js/tutorials/node↩